This is the third post in a series about data archiving to removable media (optical discs and hard drives). In the first, I
explained the difference between backing up and archiving, established goals for the project, and said I d evaluate git-annex and dar. The
second post evaluated git-annex, and now it s time to look at dar. The series will conclude with a post comparing git-annex with dar.
What is dar?
I could open with the same thing I did with git-annex, just changing the name of the program: [dar] is a fantastic and versatile program that does well, it s one of those things that can do so much that it s a bit hard to describe. It is, fundamentally, an archiver like tar or zip (makes one file representing a bunch of other files), but it goes far beyond that.
dar s homepage lays out a comprehensive
list of features, which I will try to summarize here.
- Dar itself is both a library (with C++ and Python bindings) for interacting with data, and a CLI tool (dar itself).
- Alongside this, there is an ecosystem of tools around dar, including GUIs for multiple platforms, backup scripts, and FUSE implementations.
- Dar is like tar in that it can read and write files sequentially if desired. Dar archives can be streamed, just like tar archives. But dar takes it further; if you have dar_slave on the remote end, random access is possible over ssh (dramatically speeding up certain operations).
- Dar is like zip in that a dar archive contains a central directory (called a catalog) which permits random access to the contents of an archive. In other words, you don t have to read an entire archive to extract just one file (assuming the archive is on disk or something that itself permits random access). Also, dar can compress each file individually, rather than the tar approach of compressing the archive as a whole. This increases archive performance (dar knows not to try to compress already-compressed data), boosts restore resilience (corruption of one part of an archive doesn t invalidate the entire rest of it), and boosts restore performance (permitting random access).
- Dar can split an archive into multiple pieces called slices, and it can even split member files among the slices. The catalog contains information allowing you to know which slice(s) a given file is saved in.
- The catalog can also be saved off in a file of its own (dar calls this an isolated catalog ). Isolated catalogs record just metadata about files archived.
- dar_manager can assemble a database by reading archives or isolated catalogs, letting you know where files are stored and facilitating restores using the minimal number of discs.
- Dar supports differential/incremental backups, which record changes since the last backup. These backups record not just additions, but also deletions. dar can optionally use rsync-style binary deltas to minimize the space needed to record changes. Dar does not suffer from GNU tar s data loss bug with incrementals.
- Dar can slice and dice archives like Perl does strings. The usage notes page shows how you can merge archives, create decremental archives (where the full backup always reflects the current state of the system, and incrementals go backwards in time instead of forwards), etc. You can change the compression algorithm on an existing archive, re-slice it, etc.
- Dar is extremely careful about preserving all metadata: hard links, sparse files, symlinks, timestamps (including subsecond resolution), EAs, POSIX ACLs, resource forks on Mac, detecting files being modified while being read, etc. It makes a nice way to copy directories, sort of similar to rsync -avxHAXS.
So to tie this together for this project, I will set up a 400MB slice size (to mimic what I did with git-annex), and see how dar saves the data and restores it.
Isolated cataloges aren t strictly necessary for this, but by using them (and/or dar_manager), we can build up a database of files and locations and thus directly compare dar to git-annex location tracking.
Walkthrough: Creating the first archive
As with the git-annex walkthrough, I ll set some variables to make it easy to remember:
- $SOURCEDIR is the directory being backed up
- $DRIVE is the directory for backups to be stored in. Since dar can split by a specified size, I don t need to make separate filesystems to simulate the separate drive experience as I did with git-annex.
- $CATDIR will hold isolated catalogs
- $DARDB points to the dar_manager database
OK, we can run the backup immediately. No special setup is needed. dar supports both short-form (single-character) parameters and long-form ones. Since the parameters probably aren t familiar to everyone, I will use the long-form ones in these examples.
Here s how we create our initial full backup. I ll explain the parameters below:
$ dar \
--verbose \
--create $DRIVE/bak1 \
--on-fly-isolate $CATDIR/bak1 \
--slice 400M \
--min-digits 2 \
--pause \
--fs-root $SOURCEDIR
Let s look at each of these parameters:
- verbose does what you expect
- create selects the operation mode (like tar -c) and gives the archive basename
- on-fly-isolate says to write an isolated catalog as well, right while making the archive. You can always create an isolated catalog later (which is fast, since it only needs to read the last bits of the last slice) but it s more convenient to do it now, so we do. We give the base name for the isolated catalog also.
- slice 400M says to split the archive, and create slices 400MB each.
- min-digits 2 pertains to naming files. Without it, dar would create files named bak1.dar.1, bak1.dar.2, bak1.dar.10, etc. dar works fine with this, but it can be annoying in ls. This is just convenience for humans.
- pause tells dar to pause after writing each slice. This would let us swap drives, burn discs, etc. I do this for demonstration purposes only; it isn t strictly necessary in this situation. For a more powerful option, dar also supports execute, which can run commands after each slice.
- fs-root gives the path to actually back up.
This same command could have been written with short options as:
$ dar -v -c $DRIVE/bak1 -@ $CATDIR/bak1 -s 400M -9 2 -p -R $SOURCEDIR
What does it look like while running? Here s an excerpt:
...
Adding file to archive: /acrypt/no-backup/jgoerzen/testdata/[redacted]
Finished writing to file 1, ready to continue ? [return = YES Esc = NO]
...
Writing down archive contents...
Closing the escape layer...
Writing down the first archive terminator...
Writing down archive trailer...
Writing down the second archive terminator...
Closing archive low layer...
Archive is closed.
--------------------------------------------
581 inode(s) saved
including 0 hard link(s) treated
0 inode(s) changed at the moment of the backup and could not be saved properly
0 byte(s) have been wasted in the archive to resave changing files
0 inode(s) with only metadata changed
0 inode(s) not saved (no inode/file change)
0 inode(s) failed to be saved (filesystem error)
0 inode(s) ignored (excluded by filters)
0 inode(s) recorded as deleted from reference backup
--------------------------------------------
Total number of inode(s) considered: 581
--------------------------------------------
EA saved for 0 inode(s)
FSA saved for 581 inode(s)
--------------------------------------------
Making room in memory (releasing memory used by archive of reference)...
Now performing on-fly isolation...
...
That was easy! Let s look at the contents of the backup directory:
$ ls -lh $DRIVE
total 3.7G
-rw-r--r-- 1 jgoerzen jgoerzen 400M Jun 16 19:27 bak1.01.dar
-rw-r--r-- 1 jgoerzen jgoerzen 400M Jun 16 19:27 bak1.02.dar
-rw-r--r-- 1 jgoerzen jgoerzen 400M Jun 16 19:27 bak1.03.dar
-rw-r--r-- 1 jgoerzen jgoerzen 400M Jun 16 19:27 bak1.04.dar
-rw-r--r-- 1 jgoerzen jgoerzen 400M Jun 16 19:28 bak1.05.dar
-rw-r--r-- 1 jgoerzen jgoerzen 400M Jun 16 19:28 bak1.06.dar
-rw-r--r-- 1 jgoerzen jgoerzen 400M Jun 16 19:28 bak1.07.dar
-rw-r--r-- 1 jgoerzen jgoerzen 400M Jun 16 19:28 bak1.08.dar
-rw-r--r-- 1 jgoerzen jgoerzen 400M Jun 16 19:29 bak1.09.dar
-rw-r--r-- 1 jgoerzen jgoerzen 156M Jun 16 19:33 bak1.10.dar
And the isolated catalog:
$ ls -lh $CATDIR
total 37K
-rw-r--r-- 1 jgoerzen jgoerzen 35K Jun 16 19:33 bak1.1.dar
The isolated catalog is stored compressed automatically.
Well this was easy. With one command, we archived the entire data set, split into 400MB chunks, and wrote out the catalog data.
Walkthrough: Inspecting the saved archive
Can dar tell us which slice contains a given file? Sure:
$ dar --list $DRIVE/bak1 --list-format=slicing less
Slice(s) [Data ][D][ EA ][FSA][Compr][S] Permission Filemane
--------+--------------------------------+----------+-----------------------------
...
1 [Saved][ ] [-L-][ 0%][X] -rwxr--r-- [redacted]
1-2 [Saved][ ] [-L-][ 0%][X] -rwxr--r-- [redacted]
2 [Saved][ ] [-L-][ 0%][X] -rwxr--r-- [redacted]
...
This illustrates the transition from slice 1 to slice 2. The first file was stored entirely in slice 1; the second stored partially in slice 1 and partially in slice 2, and third solely in slice 2. We can get other kinds of information as well.
$ dar --list $DRIVE/bak1 less
[Data ][D][ EA ][FSA][Compr][S] Permission User Group Size Date filename
--------------------------------+------------+-------+-------+---------+-------------------------------+------------
[Saved][ ] [-L-][ 0%][X] -rwxr--r-- jgoerzen jgoerzen 24 Mio Mon Mar 5 07:58:09 2018 [redacted]
[Saved][ ] [-L-][ 0%][X] -rwxr--r-- jgoerzen jgoerzen 16 Mio Mon Mar 5 07:58:09 2018 [redacted]
[Saved][ ] [-L-][ 0%][X] -rwxr--r-- jgoerzen jgoerzen 22 Mio Mon Mar 5 07:58:09 2018 [redacted]
These are the same files I was looking at before. Here we see they are 24MB, 16MB, and 22MB in size, and some additional metadata. Even more is available in the XML list format.
Walkthrough: updates
As with git-annex, I ve made some changes in the source directory: moved a file, added another, and deleted one. Let s create an incremental backup now:
$ dar \
--verbose \
--create $DRIVE/bak2 \
--on-fly-isolate $CATDIR/bak2 \
--ref $CATDIR/bak1 \
--slice 400M \
--min-digits 2 \
--pause \
--fs-root $SOURCEDIR
This command is very similar to the earlier one. Instead of writing an archive and catalog named bak1, we write one named bak2. What s new here is
--ref $CATDIR/bak1. That says, make an incremental based on an archive of reference. All that is needed from that archive of reference is the detached catalog.
--ref $DRIVE/bak1 would have worked equally well here.
Here s what I did to the $SOURCEDIR:
- Renamed a file to file01-unchanged
- Deleted a file
- Copied /bin/cp to a file named cp
Let s see if dar s command output matches this:
...
Adding file to archive: /acrypt/no-backup/jgoerzen/testdata/file01-unchanged
Saving Filesystem Specific Attributes for /acrypt/no-backup/jgoerzen/testdata/file01-unchanged
Adding file to archive: /acrypt/no-backup/jgoerzen/testdata/cp
Saving Filesystem Specific Attributes for /acrypt/no-backup/jgoerzen/testdata/cp
Adding folder to archive: [redacted]
Saving Filesystem Specific Attributes for [redacted]
Adding reference to files that have been destroyed since reference backup...
...
--------------------------------------------
3 inode(s) saved
including 0 hard link(s) treated
0 inode(s) changed at the moment of the backup and could not be saved properly
0 byte(s) have been wasted in the archive to resave changing files
0 inode(s) with only metadata changed
578 inode(s) not saved (no inode/file change)
0 inode(s) failed to be saved (filesystem error)
0 inode(s) ignored (excluded by filters)
2 inode(s) recorded as deleted from reference backup
--------------------------------------------
Total number of inode(s) considered: 583
--------------------------------------------
EA saved for 0 inode(s)
FSA saved for 3 inode(s)
--------------------------------------------
...
Yes, it does. The rename is recorded as a deletion and an addition, since dar doesn t directly track renames. So the rename plus the deletion account for the two deletions. The rename plus the addition of cp count as 2 of the 3 inodes saved; the third is the modified directory from which files were deleted and moved out.
Let s see the files that were created:
$ ls -lh $DRIVE/bak2*
-rw-r--r-- 1 jgoerzen jgoerzen 18M Jun 16 19:52 /acrypt/no-backup/jgoerzen/dar-testing/drive/bak2.01.dar
$ ls -lh $CATDIR/bak2*
-rw-r--r-- 1 jgoerzen jgoerzen 22K Jun 16 19:52 /acrypt/no-backup/jgoerzen/dar-testing/cat/bak2.1.dar
What does list look like now?
Slice(s) [Data ][D][ EA ][FSA][Compr][S] Permission Filemane
--------+--------------------------------+----------+-----------------------------
[ ][ ] [---][-----][X] -rwxr--r-- [redacted]
1 [Saved][ ] [-L-][ 0%][X] -rwxr--r-- file01-unchanged
...
[--- REMOVED ENTRY ----][redacted]
[--- REMOVED ENTRY ----][redacted]
Here I show an example of:
- A file that was not changed from the initial backup. Its presence was simply noted, but because we re doing an incremental, the data wasn t saved.
- A file that is saved in this incremental, on slice 1.
- The two deleted files
Walkthrough: dar_manager
As we ve seen above, the two archives (or their detached catalog) give us a complete picture of what files were present at the time of the creation of each archive, and what files were stored in a given archive. We can certainly continue working in that way. We can also use dar_manager to build a comprehensive database of these archives, to be able to find what media is necessary to restore each given file. Or, with dar_manager s when parameter, we can restore files as of a particular date.
Let s try it out. First, we create our database:
$ dar_manager --create $DARDB
$ dar_manager --base $DARDB --add $DRIVE/bak1
Auto detecting min-digits to be 2
$ dar_manager --base $DARDB --add $DRIVE/bak2
Auto detecting min-digits to be 2
Here we created the database, and added our two catalogs to it. (Again, we could have as easily used $CATDIR/bak1; either the archive or its isolated catalog will work here.) It s important to add the catalogs in order.
Let s do some quick experimentation with dar_manager:
$ dar_manager -v --base $DARDB --list
Decompressing and loading database to memory...
dar path :
dar options :
database version : 6
compression used : gzip
compression level: 9
archive # path basename
------------+--------------+---------------
1 /acrypt/no-backup/jgoerzen/dar-testing/drive bak1
2 /acrypt/no-backup/jgoerzen/dar-testing/drive bak2
$ dar_manager --base $DARDB --stat
archive # most recent/total data most recent/total EA
--------------+-------------------------+-----------------------
1 580/581 0/0
2 3/3 0/0
The list option shows the correlation between dar_manager archive number (1, 2) with filenames (bak1, bak2). It is coincidence here that 1/bak1 and 2/bak2 correlate; that s not necessarily the case. Most dar_manager commands operate on archive number, while dar commands operate on archive path/basename.
Now let s see just what files are saved in archive
#2, the incremental:
$ dar_manager --base $DARDB --used 2
[ Saved ][ ] [redacted]
[ Saved ][ ] file01-unchanged
[ Saved ][ ] cp
Now we can also where a file is stored. Here s one that was saved in the full backup and unmodified in the incremental:
$ dar_manager --base $DARDB --file [redacted]
1 Fri Jun 16 19:15:12 2023 saved absent
2 Fri Jun 16 19:15:12 2023 present absent
(The absent at the end refers to extended attributes that the file didn t have)
Similarly, for files that were added or removed, they ll be listed only at the appropriate place.
Walkthrough: Restoration
I m not going to repeat the author s full
restoration with dar page, but here are some quick examples.
A simple way of doing everything is using incrementals for the whole series. To do that, you d have bak1 be full, bak2 based on bak1, bak3 based on bak2, bak4 based on bak3, etc. To restore from such a series, you have two options:
- Use dar to simply extract each archive in order. It will handle deletions, renames, etc. along the way.
- Use dar_manager with the backup database to do manage the process. It may be somewhat more efficient, as it won t bother to restore files that will later be modified or deleted.
If you get fancy for instance, bak2 is based on bak1, bak3 on bak2, bak4 on bak1 then you would want to use dar_manager to ensure a consistent restore is completed. Either way, the process is nearly identical. Also, I figure, to make things easy, you can save a copy of the entire set of isolated catalogs before you finalize each disc/drive. They re so small, and this would let someone with just the most recent disc build a dar_manager database without having to go through all the other discs.
Anyhow, let s do a restore using just dar. I ll make a $RESTOREDIR and do it that way.
$ dar \
--verbose \
--extract $DRIVE/bak1 \
--fs-root $RESTOREDIR \
--no-warn \
--execute "echo Ready for slice %n. Press Enter; read foo"
This execute lets us see how dar works; this is an illustration of the power it has (above pause); it s a snippet interpreted by /bin/sh with %n being one of the dar placeholders. If memory serves, it s not strictly necessary, as dar will prompt you for slices it needs if they re not mounted. Anyhow, you ll see it first reading the last slice, which contains the catalog, then reading from the beginning.
Here we go:
Auto detecting min-digits to be 2
Opening archive bak1 ...
Opening the archive using the multi-slice abstraction layer...
Ready for slice 10. Press Enter
...
Loading catalogue into memory...
Locating archive contents...
Reading archive contents...
File ownership will not be restored du to the lack of privilege, you can disable this message by asking not to restore file ownership [return = YES Esc = NO]
Continuing...
Restoring file's data: [redacted]
Restoring file's FSA: [redacted]
Ready for slice 1. Press Enter
...
Ready for slice 2. Press Enter
...
--------------------------------------------
581 inode(s) restored
including 0 hard link(s)
0 inode(s) not restored (not saved in archive)
0 inode(s) not restored (overwriting policy decision)
0 inode(s) ignored (excluded by filters)
0 inode(s) failed to restore (filesystem error)
0 inode(s) deleted
--------------------------------------------
Total number of inode(s) considered: 581
--------------------------------------------
EA restored for 0 inode(s)
FSA restored for 0 inode(s)
--------------------------------------------
The warning is because I m not doing the extraction as root, which limits dar s ability to fully restore ownership data.
OK, now the incremental:
$ dar \
--verbose \
--extract $DRIVE/bak2 \
--fs-root $RESTOREDIR \
--no-warn \
--execute "echo Ready for slice %n. Press Enter; read foo"
...
Ready for slice 1. Press Enter
...
Restoring file's data: /acrypt/no-backup/jgoerzen/dar-testing/restore/file01-unchanged
Restoring file's FSA: /acrypt/no-backup/jgoerzen/dar-testing/restore/file01-unchanged
Restoring file's data: /acrypt/no-backup/jgoerzen/dar-testing/restore/cp
Restoring file's FSA: /acrypt/no-backup/jgoerzen/dar-testing/restore/cp
Restoring file's data: /acrypt/no-backup/jgoerzen/dar-testing/restore/[redacted directory]
Removing file (reason is file recorded as removed in archive): [redacted file]
Removing file (reason is file recorded as removed in archive): [redacted file]
This all looks right! Now how about we compare the restore to the original source directory?
$ diff -durN $SOURCEDIR $RESTOREDIR
No changes perfect.
We could instead do this restore via a single dar_manager command, though annoyingly, we d have to pass all top-level files/directories to dar_manager restore. But still, it s one command, and basically automates and optimizes the dar restores shown above.
Conclusions
Dar makes it extremely easy to just Do The Right Thing when making archives. One command makes a backup. It saves things in simple files. You can make an isolated catalog if you want, and it too is saved in a simple file. You can query what is in the files and where. You can restore from all or part of the files. You can simply play the backups forward, in order, to achieve a full and consistent restore. Or you can load data about them into dar_manager for an optimized restore.
A bit of scripting will be necessary to make incrementals; finding the most recent backup or catalog. If backup files are named with care for instance, by date then this should be a pretty easy task.
I haven t touched on resiliency yet. dar comes with tools for recovering archives that have had portions corrupted or lost. It can also rebuild the catalog if it is corrupted or lost. It adds tape marks (or escape sequences ) to the archive along with the data stream. So every entry in the catalog is actually stored in the archive twice: once alongside the file data, and once at the end in the collected catalog. This allows dar to scan a corrupted file for the tape marks and reconstruct whatever is still intact, even if the catalog is lost. dar also integrates with tools like sha256sum and
par2 to simplify archive integrity testing and restoration.
This balances against the need to use a tool (dar, optionally with a GUI frontend) to restore files. I ll discuss that more in the next post.
 About 6 months ago, I decided to purchase a bike trailer. I don't drive and
although I also have a shopping caddy, it often can't handle a week's
groceries.
About 6 months ago, I decided to purchase a bike trailer. I don't drive and
although I also have a shopping caddy, it often can't handle a week's
groceries.
 Since the goal for the trailer was to haul encumbering and heavy loads, I
decided to splurge and got a Surly Ted. The 32" x 24" flat bed is very
versatile and the trailer is rated for up to 300 lbs (~135 kg).
At around 30 lbs (~13.5 kg), the trailer itself is light enough for me to climb
up the stairs to my apartment with it.
Having seldom driven a bike trailer before, I was at first worried about its
handling and if it would jerk me around (as some children's chariots tend to).
I'm happy to report the two pronged hitch Surly designed works very
well and lets you do 180 turns effortlessly.
Since the goal for the trailer was to haul encumbering and heavy loads, I
decided to splurge and got a Surly Ted. The 32" x 24" flat bed is very
versatile and the trailer is rated for up to 300 lbs (~135 kg).
At around 30 lbs (~13.5 kg), the trailer itself is light enough for me to climb
up the stairs to my apartment with it.
Having seldom driven a bike trailer before, I was at first worried about its
handling and if it would jerk me around (as some children's chariots tend to).
I'm happy to report the two pronged hitch Surly designed works very
well and lets you do 180 turns effortlessly.
 So far, I've used the trailer to go grocery shopping, buy bulk food and haul
dirt and mulch. To make things easier, I've purchased two 45L storing
crates from Home Depot and added two planks of wood on each side of
the trailer to stabilise things when I strap the crates down to the bed.
Since my partner and I are subscribed to an organic farmer's box during the
summer and get baskets from Lufa during the winter, picking up our
groceries at the pick-up point is as easy as dumping our order in the storing
crates and strapping them back to the trailer.
So far, I've used the trailer to go grocery shopping, buy bulk food and haul
dirt and mulch. To make things easier, I've purchased two 45L storing
crates from Home Depot and added two planks of wood on each side of
the trailer to stabilise things when I strap the crates down to the bed.
Since my partner and I are subscribed to an organic farmer's box during the
summer and get baskets from Lufa during the winter, picking up our
groceries at the pick-up point is as easy as dumping our order in the storing
crates and strapping them back to the trailer.
 Although my housing cooperative has a (small) indoor bicycle parking space, my
partner uses our spot during the summer, which means I have to store the
trailer on my balcony. To make things more manageable and free up some space, I
set up a system of pulleys to hoist the trailer up the air when it's not in
use.
I did go through a few iterations, but I'm pretty happy with the current 8
pulleys block and tackle mechanism I rigged.
Although my housing cooperative has a (small) indoor bicycle parking space, my
partner uses our spot during the summer, which means I have to store the
trailer on my balcony. To make things more manageable and free up some space, I
set up a system of pulleys to hoist the trailer up the air when it's not in
use.
I did go through a few iterations, but I'm pretty happy with the current 8
pulleys block and tackle mechanism I rigged.
 All and all, this trailer wasn't cheap, but I regret nothing. Knowing Surley's
reputation, it will last me many years and not having to drive a car to get
around always ends up being the cheaper solution.
All and all, this trailer wasn't cheap, but I regret nothing. Knowing Surley's
reputation, it will last me many years and not having to drive a car to get
around always ends up being the cheaper solution.
 Since some time I ve been thinking about making myself a top or a dress with a wide gathered neckline that can be work at different widths, including off-the-shoulders.
A few years ago I ve been gifted a cut of nice, thin white fabric with a print of lines and lozenges that isn t uniform along the fabric, but looks like it was designed for some specific garment, and it was waiting in my stash for a suitable pattern.
And a few days ago, during a Sunday lunch, there was an off-hand mention of a dress from the late 1970s which had an elastic in the neckline, so that it could be optionally worn off-the-shoulders.
And something snapped in place.
I had plans for that afternoon, but they were scrapped, and I started to draw, measure, cut rectangles of fabric, pin and measure again, cut more fabric.
Since some time I ve been thinking about making myself a top or a dress with a wide gathered neckline that can be work at different widths, including off-the-shoulders.
A few years ago I ve been gifted a cut of nice, thin white fabric with a print of lines and lozenges that isn t uniform along the fabric, but looks like it was designed for some specific garment, and it was waiting in my stash for a suitable pattern.
And a few days ago, during a Sunday lunch, there was an off-hand mention of a dress from the late 1970s which had an elastic in the neckline, so that it could be optionally worn off-the-shoulders.
And something snapped in place.
I had plans for that afternoon, but they were scrapped, and I started to draw, measure, cut rectangles of fabric, pin and measure again, cut more fabric.

 The part of the fabric with large vertical stripes had two different widths: I could have made the back narrower, but I decided to just keep a strip with narrower lines to one side.
The fabric also didn t have a full second strip of lozenges, so I had to hem it halfway through it.
The part of the fabric with large vertical stripes had two different widths: I could have made the back narrower, but I decided to just keep a strip with narrower lines to one side.
The fabric also didn t have a full second strip of lozenges, so I had to hem it halfway through it.
 The casing for the elastic was pieced from various scraps, but at least I was able to match the lines on the center front and back, even if they are different. Not that it matters a lot, since it s all hidden in the gathering, but I would have known.
And since I was working on something definitely modern, even if made out of squares and rectangles, of course I decided to hand-sew everything, mostly to be able to use quite small sewing allowances, since the fabric was pretty thin.
In my stash I had a piece of swimsuit elastic that feels nice, looks nice and makes a knot that doesn t slip, so I used it. It s a perfect match, except for the neon yellow colour, which I do like, but maybe is a bit too high visibility? I will see if the haberdasher has the same elastic in dark blue, but right now this will do.
It was a quick project anyway: by the end of the working week the top was finished; I think that on a sewing machine it would be easy to make it in a day.
The casing for the elastic was pieced from various scraps, but at least I was able to match the lines on the center front and back, even if they are different. Not that it matters a lot, since it s all hidden in the gathering, but I would have known.
And since I was working on something definitely modern, even if made out of squares and rectangles, of course I decided to hand-sew everything, mostly to be able to use quite small sewing allowances, since the fabric was pretty thin.
In my stash I had a piece of swimsuit elastic that feels nice, looks nice and makes a knot that doesn t slip, so I used it. It s a perfect match, except for the neon yellow colour, which I do like, but maybe is a bit too high visibility? I will see if the haberdasher has the same elastic in dark blue, but right now this will do.
It was a quick project anyway: by the end of the working week the top was finished; I think that on a sewing machine it would be easy to make it in a day.
 And it can be worn off the shoulders! Which is something I will probably never do in public (and definitely not outdoors), but now if I wanted I could! :D
As usual, the pattern (for what pattern there is) and instructions are
And it can be worn off the shoulders! Which is something I will probably never do in public (and definitely not outdoors), but now if I wanted I could! :D
As usual, the pattern (for what pattern there is) and instructions are  I m six months into my journey of building a business which means its time to reflect and review the goals I set for the year.
I m six months into my journey of building a business which means its time to reflect and review the goals I set for the year.
 I use a LUKS-encrypted USB stick to store my GPG and SSH keys, which acts as a
backup and portable key setup when working on different laptops. One
inconvenience with LUKS-encrypted USB sticks is that you need to enter the
password every time you want to mount the device, either through a Window
Manager like KDE or using the cryptsetup luksOpen command. Fortunately, many
laptops nowadays come equipped with TPM2 modules, which can be utilized to
automatically decrypt the device and subsequently mount it. In this post, we'll
explore the usage of systemd-cryptenroll for this purpose, along with udev
rules and a set of scripts to automate the mounting of the encrypted USB.
First, ensure that your device has a TPM2 module. You can run the following
command to check:
I use a LUKS-encrypted USB stick to store my GPG and SSH keys, which acts as a
backup and portable key setup when working on different laptops. One
inconvenience with LUKS-encrypted USB sticks is that you need to enter the
password every time you want to mount the device, either through a Window
Manager like KDE or using the cryptsetup luksOpen command. Fortunately, many
laptops nowadays come equipped with TPM2 modules, which can be utilized to
automatically decrypt the device and subsequently mount it. In this post, we'll
explore the usage of systemd-cryptenroll for this purpose, along with udev
rules and a set of scripts to automate the mounting of the encrypted USB.
First, ensure that your device has a TPM2 module. You can run the following
command to check:
 Reduce the size of your c: partition to the smallest it can be and then turn off windows with the understanding that you will never boot this system on the iron ever again.
Reduce the size of your c: partition to the smallest it can be and then turn off windows with the understanding that you will never boot this system on the iron ever again. To find the literal path names of your detected drives you can run fdisk -l. Pay attention to the names of the partitions and the sizes of the drives to help determine which is which.
Once you have a shell in the netinst installer, you should maybe be able to run a command like the following. This will duplicate the disk located at if (in file) to the disk located at of (out file) while showing progress as the status.
To find the literal path names of your detected drives you can run fdisk -l. Pay attention to the names of the partitions and the sizes of the drives to help determine which is which.
Once you have a shell in the netinst installer, you should maybe be able to run a command like the following. This will duplicate the disk located at if (in file) to the disk located at of (out file) while showing progress as the status.
 In the New VM window, select Import existing disk image
In the New VM window, select Import existing disk image 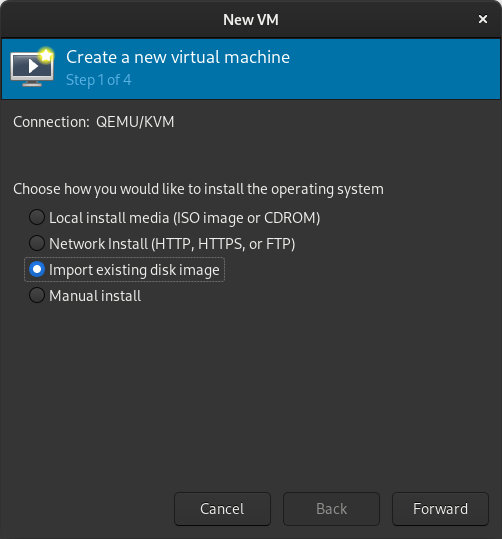 When prompted for the path to the image, use the one we created with sudo qemu-img convert above.
When prompted for the path to the image, use the one we created with sudo qemu-img convert above.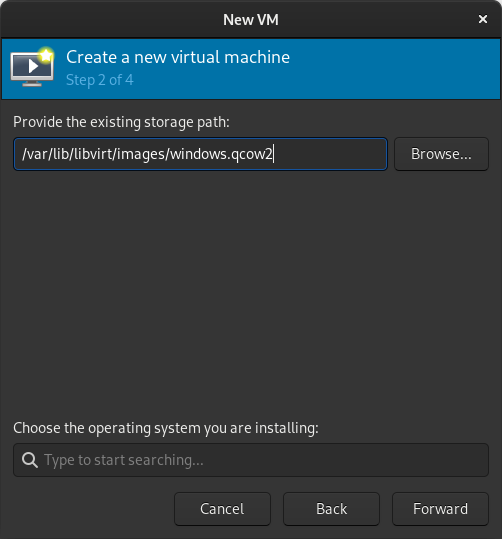 Select the version of Windows you want.
Select the version of Windows you want.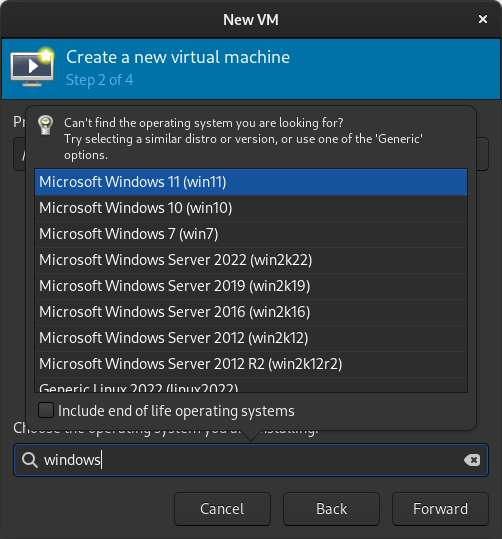 Select memory and CPUs to allocate to the VM.
Select memory and CPUs to allocate to the VM.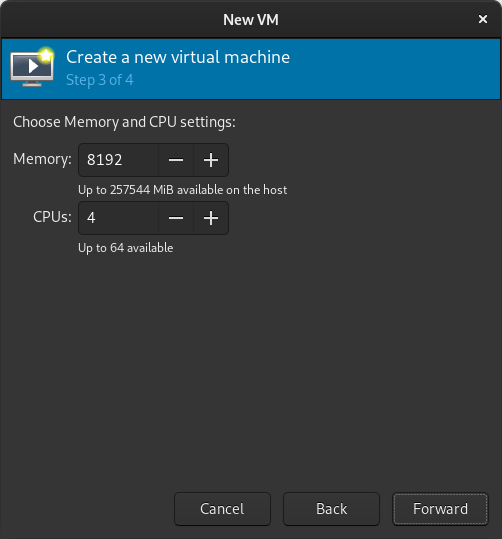 Tick the Customize configuration before install box
Tick the Customize configuration before install box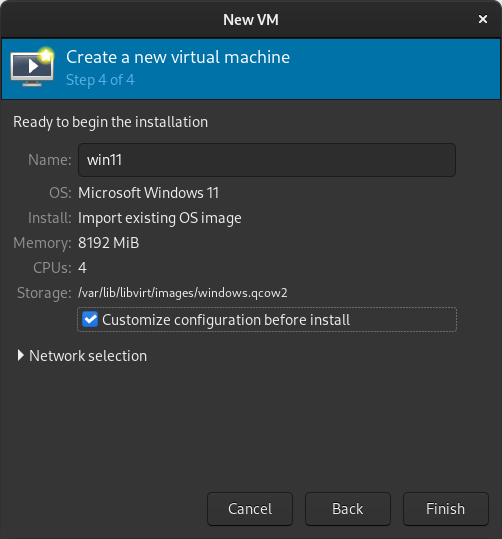 If you re prompted to enable the default network, do so now.
If you re prompted to enable the default network, do so now.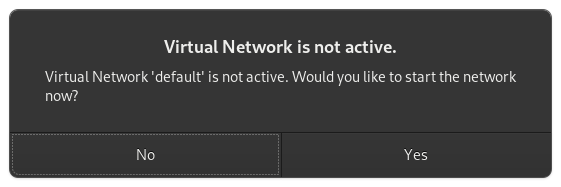 The default hardware layout should probably suffice. Get it as close to the underlying hardware as it is convenient to do. But Windows is pretty lenient these days about virtualizing licensed windows instances so long as they re not running in more than one place at a time.
The default hardware layout should probably suffice. Get it as close to the underlying hardware as it is convenient to do. But Windows is pretty lenient these days about virtualizing licensed windows instances so long as they re not running in more than one place at a time.
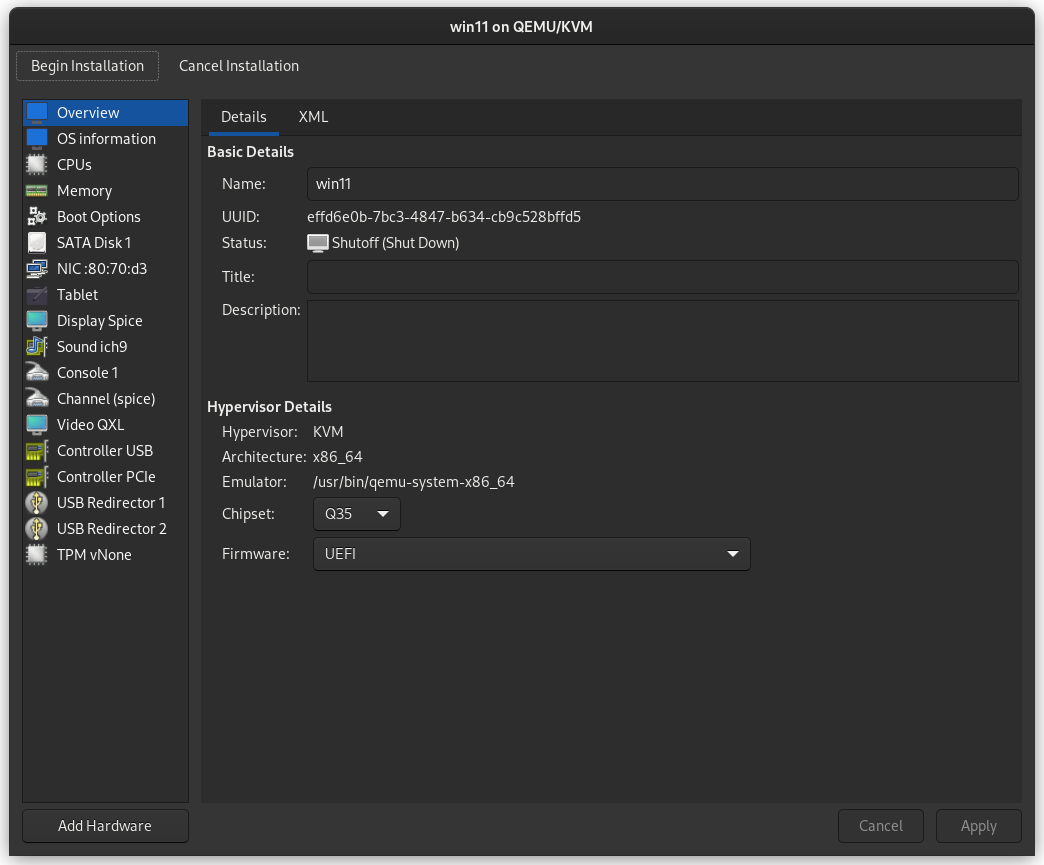 Good luck! Leave comments if you have questions.
Good luck! Leave comments if you have questions.
 Since before I got involved in the eID
Since before I got involved in the eID 






 I've moved to having containers be first-class citizens on my home network, so
any local machine (laptop, phone,tablet) can communicate directly with them all,
but they're not (by default) exposed to the wider Internet. Here's why, and how.
After
I've moved to having containers be first-class citizens on my home network, so
any local machine (laptop, phone,tablet) can communicate directly with them all,
but they're not (by default) exposed to the wider Internet. Here's why, and how.
After  Did you follow the instructions linked above in the prerequisites section? If not, take a moment to do so now.
Did you follow the instructions linked above in the prerequisites section? If not, take a moment to do so now. You may be warned that Rufus will be acting as dd.
You may be warned that Rufus will be acting as dd. Don t forget to select the USB drive that you want to write the image to. In my example, the device is creatively called NO_LABEL .
Don t forget to select the USB drive that you want to write the image to. In my example, the device is creatively called NO_LABEL . You may be warned that re-imaging the USB disk will result in the previous data on the USB disk being lost.
You may be warned that re-imaging the USB disk will result in the previous data on the USB disk being lost. Once the process is complete, the application will indicate that it is complete.
Once the process is complete, the application will indicate that it is complete. You should now have a USB disk with the Proxmox installer image on it. Place the USB disk into one of the blue, USB-3.0, USB-A slots on the Qotom device so that the system can read the installer image from it at full speed. The Proxmox installer requires a keyboard, video and mouse. Please attach these to the device along with inserting the USB disk you just created.
You should now have a USB disk with the Proxmox installer image on it. Place the USB disk into one of the blue, USB-3.0, USB-A slots on the Qotom device so that the system can read the installer image from it at full speed. The Proxmox installer requires a keyboard, video and mouse. Please attach these to the device along with inserting the USB disk you just created.
 Press the power button on the Qotom device. Press the F11 key repeatedly until you see the AMI BIOS menu. Press F11 a couple more times. You ll be presented with a boot menu. One of the options will launch the Proxmox installer. By trial and error, I found that the correct boot menu option was UEFI OS
Press the power button on the Qotom device. Press the F11 key repeatedly until you see the AMI BIOS menu. Press F11 a couple more times. You ll be presented with a boot menu. One of the options will launch the Proxmox installer. By trial and error, I found that the correct boot menu option was UEFI OS
 Once you select the correct option, you will be presented with a menu that looks like this. Select the default option and install.
Once you select the correct option, you will be presented with a menu that looks like this. Select the default option and install.
 During the install, you will be presented with an option of the block device to install to. I think there s only a single block device in this celeron, but if there are more than one, I prefer the smaller one for the ProxMox OS. I also make a point to limit the size of the root filesystem to 16G. I think it will take up the entire volume group if you don t set a limit.
Okay, I ll do another install and select the correct filesystem.
During the install, you will be presented with an option of the block device to install to. I think there s only a single block device in this celeron, but if there are more than one, I prefer the smaller one for the ProxMox OS. I also make a point to limit the size of the root filesystem to 16G. I think it will take up the entire volume group if you don t set a limit.
Okay, I ll do another install and select the correct filesystem.
 If you read this far and want me to add some more screenshots and better instructions, leave a comment.
If you read this far and want me to add some more screenshots and better instructions, leave a comment.
 Way back at
Way back at {kind=link}
{kind=link}